Mô hình trí tuệ nhân tạo tiên tiến nhất dành cho công việc chuyên nghiệp và các tác vụ yêu cầu xử lý liên tục, lâu dài.
Chúng tôi xin giới thiệu GPT‑5.2 – thế hệ mô hình mạnh mẽ nhất từ trước đến nay, được phát triển đặc biệt dành cho những nhiệm vụ đòi hỏi tư duy sâu và kiến thức chuyên môn.
Theo kết quả khảo sát, người dùng ChatGPT phiên bản doanh nghiệp cho biết AI giúp họ tiết kiệm trung bình từ 40–60 phút mỗi ngày; riêng những người dùng tích cực có thể tiết kiệm hơn 10 giờ mỗi tuần. GPT‑5.2 được xây dựng nhằm gia tăng hiệu quả kinh tế cho người dùng, với khả năng vượt trội trong việc xử lý bảng tính, thiết kế bài thuyết trình, lập trình, nhận diện hình ảnh, hiểu ngữ cảnh văn bản dài, sử dụng công cụ và giải quyết các dự án nhiều bước phức tạp.
GPT‑5.2 đã lập nên các mốc mới trên hàng loạt tiêu chí, trong đó có GDPval – bài kiểm tra nơi mô hình này vượt qua các chuyên gia ở những nhiệm vụ chuyên môn, trải rộng trên 44 lĩnh vực khác nhau.
| GPT-5.2 Thinking | GPT-5.1 Thinking | |
|---|---|---|
| GDPval (thắng hoặc hòa) Công việc chuyên môn | 70.9% | 38.8% (GPT‑5) |
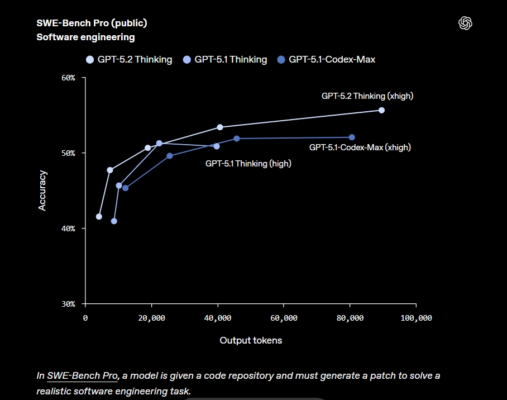
| SWE-Bench Pro (công khai) Kỹ sư phần mềm | 55.6% | 50.8% |
| SWE-bench Verified Kỹ sư phần mềm | 80.0% | 76.3% |
| GPQA Diamond (không công cụ) Hỏi đáp khoa học | 92.4% | 88.1% |
| CharXiv Reasoning (với Python) Câu hỏi lý luận hình học | 88.7% | 80.3% |
| AIME 2025 (không công cụ) Toán học thi đấu | 100.0% | 94.0% |
| FrontierMath (Tier 1–3) Toán nâng cao | 40.3% | 31.0% |
| FrontierMath (Tier 4) Toán nâng cao | 14.6% | 12.5% |
| ARC-AGI-1 (Verified) Lý luận trừu tượng | 86.2% | 72.8% |
| ARC-AGI-2 (Verified) Lý luận trừu tượng | 52.9% | 17.6% |
Ngay từ hôm nay, người dùng ChatGPT phiên bản trả phí có thể trải nghiệm các phiên bản GPT‑5.2 Instant, Thinking và Pro. Trên nền tảng API, các mô hình này cũng đã sẵn sàng cho tất cả nhà phát triển.
Tổng thể, GPT‑5.2 mang lại bước tiến vượt bậc về khả năng tư duy tổng quát, xử lý văn bản dài, sử dụng công cụ như một “trợ lý ảo” và nhận diện hình ảnh, cho phép giải quyết hiệu quả hơn những tác vụ thực tế phức tạp từ đầu đến cuối, vượt xa mọi mô hình trước đây.
Hiệu suất mô hình
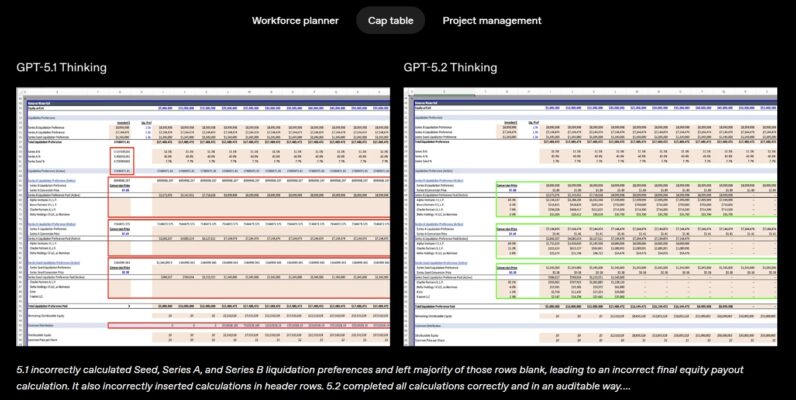
GPT‑5.2 Thinking hiện là lựa chọn tối ưu nhất cho các ứng dụng chuyên môn ngoài thực tế. Ở bài kiểm tra GDPval – đánh giá khả năng hoàn thành các nhiệm vụ kiến thức chuyên sâu trên 44 lĩnh vực – GPT‑5.2 Thinking đã xác lập kỷ lục mới, là mô hình đầu tiên đạt hoặc vượt trình độ chuyên gia con người. Cụ thể, mô hình này thể hiện ngang hoặc vượt các chuyên gia đầu ngành ở 70.9% nhiệm vụ theo đánh giá của giám khảo. Các nhiệm vụ bao gồm soạn thảo bài thuyết trình, xây dựng bảng tính và nhiều đầu mục khác. GPT‑5.2 Thinking còn có thể tạo ra sản phẩm với tốc độ nhanh hơn chuyên gia 11 lần và chi phí chỉ bằng 1%, cho thấy khi làm việc cùng chuyên gia, mô hình sẽ là “trợ thủ đắc lực” cho công việc chuyên sâu. Thông số về tốc độ và chi phí được tính dựa trên dữ liệu lịch sử; thời gian trên ChatGPT có thể thay đổi.
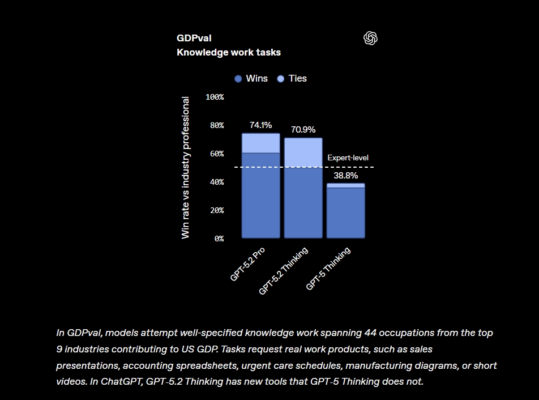
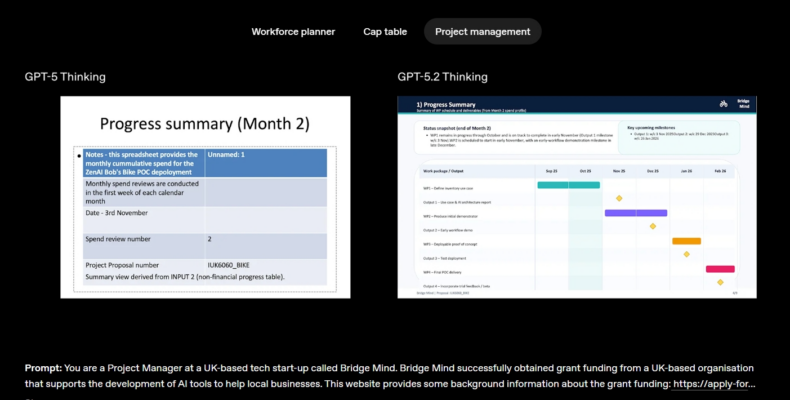
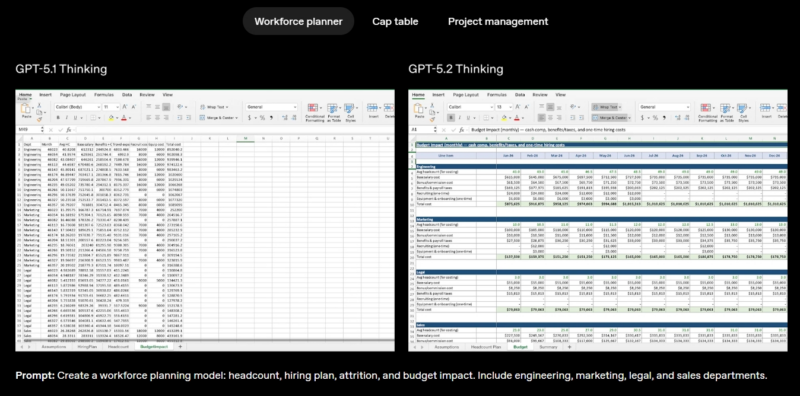
Bên cạnh đó, trong kiểm tra nội bộ với các bài toán bảng tính dành cho phân tích viên ngân hàng đầu tư (ví dụ: xây dựng mô hình tài chính cho một công ty Fortune 500 theo chuẩn quốc tế, hoặc lập kịch bản mua lại doanh nghiệp bằng đòn bẩy…), điểm số trung bình của GPT‑5.2 Thinking tăng hơn GPT‑5.1 tới 9.3%, từ 59.1% lên 68.4%.
Khi so sánh từng sản phẩm, chất lượng bảng tính và slide do GPT‑5.2 Thinking tạo ra có tính chuyên nghiệp và tinh tế vượt trội.
GPT‑5.2 Thinking cũng đạt thành tích cao nhất từ trước đến nay với 55.6% trên SWE-Bench Pro – một chuẩn đánh giá năng lực phát triển phần mềm thực tế. Khác với SWE-bench Verified (chỉ kiểm tra Python), SWE-Bench Pro kiểm tra trên bốn ngôn ngữ lập trình, có tính chống “học thuộc” cao, đa dạng và sát thực tế doanh nghiệp.
Trên SWE-bench Verified, GPT‑5.2 Thinking đạt 80% – điểm số cao nhất lịch sử.
GPT‑5.2 Thinking giảm thiểu rõ rệt tình trạng “bịa đặt thông tin” thường gặp ở AI (“hallucination”) so với GPT‑5.1 Thinking. Trên một bộ truy vấn ẩn danh từ ChatGPT, số câu trả lời sai giảm tới 30%. Đối với người làm chuyên môn, điều này giúp hạn chế lỗi khi sử dụng mô hình cho nghiên cứu, viết lách, phân tích hoặc hỗ trợ ra quyết định – nâng cao độ tin cậy trong các công việc hàng ngày.
Tuy nhiên, GPT‑5.2 Thinking vẫn chưa hoàn hảo. Khi xử lý các tác vụ quan trọng, hãy luôn kiểm tra lại kết quả.
Khả năng xử lý văn bản dài
GPT‑5.2 Thinking thiết lập chuẩn mới về năng lực tư duy với văn bản dài, đạt kết quả dẫn đầu ở OpenAI MRCRv2 – bài kiểm tra khả năng tổng hợp thông tin phân tán trong tài liệu lớn. Với các nhiệm vụ thực tế như phân tích tài liệu hàng trăm nghìn tokens, GPT‑5.2 Thinking cho kết quả chính xác vượt trội so với GPT‑5.1 Thinking. Đây cũng là mô hình đầu tiên đạt gần 100% chính xác với biến thể MRCR 4-needle (tới 256 nghìn tokens).
Thực tế, điều này cho phép chuyên gia tận dụng GPT‑5.2 để xử lý các tài liệu dài – như báo cáo, hợp đồng, nghiên cứu, biên bản, hoặc dự án nhiều file – mà vẫn đảm bảo mạch lạc, chính xác trên hàng trăm nghìn tokens. GPT‑5.2 rất phù hợp với các bài toán tổng hợp, phân tích sâu và quy trình phức tạp cần thu thập dữ liệu từ nhiều nguồn.
Với những tác vụ cần trí tuệ vượt khỏi giới hạn cửa sổ ngữ cảnh mặc định, GPT‑5.2 Thinking còn hỗ trợ endpoint Responses /compact, giúp mô hình xử lý hiệu quả hơn các workflow (quy trình làm việc) kéo dài hoặc sử dụng nhiều công cụ, không bị rào cản về độ dài văn bản. Bạn có thể xem chi tiết trong tài liệu API.
Ngoài ra, GPT‑5.2 Thinking hiện là mô hình có năng lực thị giác mạnh nhất, giảm hơn một nửa tỷ lệ lỗi ở các bài toán lý luận biểu đồ và nhận diện giao diện phần mềm.
So với các mô hình trước, GPT‑5.2 Thinking xác định vị trí, bố cục các thành phần trong hình ảnh tốt hơn, rất hữu ích với các tác vụ mà mối liên hệ vị trí là then chốt. Ví dụ dưới đây, chúng tôi yêu cầu mô hình xác định các bộ phận trên một bo mạch chủ và đưa ra nhãn cùng khung giới hạn tương ứng. Dù ảnh chất lượng thấp, GPT‑5.2 vẫn xác định chính xác các vùng trọng yếu, vẽ khung gần như trùng khớp với thực tế; trong khi GPT‑5.1 chỉ gán nhãn một số thành phần và hiểu sai bố cục không gian. Cả hai đều có điểm chưa hoàn hảo, nhưng GPT‑5.2 cho thấy khả năng “nhìn” vượt trội.
GPT-5.1

GPT-5.2

GPT‑5.2 Thinking đạt điểm 98.7% trên Tau2-bench Telecom – thể hiện năng lực sử dụng công cụ ổn định và chính xác qua các nhiệm vụ dài, nhiều lượt trao đổi.
Với các tình huống cần phản hồi nhanh, GPT‑5.2 Thinking vẫn thể hiện khả năng lý luận vượt trội ở chế độ reasoning.effort=’none’, vượt xa GPT‑5.1 và GPT‑4.1.
Ví dụ, khi gặp yêu cầu hỗ trợ khách hàng phức tạp gồm nhiều bước (ví dụ: khách báo chuyến bay trễ, lỡ nối chuyến, cần lưu trú qua đêm ở New York và có yêu cầu đặc biệt về chỗ ngồi), GPT‑5.2 có thể phối hợp trơn tru toàn bộ quy trình – đặt lại vé, hỗ trợ chỗ ngồi đặc biệt và xử lý bồi thường – cho kết quả trọn vẹn hơn hẳn so với GPT‑5.1.
GPT-5.1

GPT-5.2

Một trong những mục tiêu lớn của chúng tôi là dùng AI thúc đẩy nghiên cứu khoa học vì cộng đồng. Chúng tôi đã hợp tác với các nhà khoa học để thử nghiệm, lắng nghe cách AI có thể tăng tốc tiến trình nghiên cứu – và đã chia sẻ những kết quả thử nghiệm đầu tiên tại đây.
Chúng tôi tin rằng GPT‑5.2 Pro và GPT‑5.2 Thinking là các mô hình hỗ trợ nghiên cứu khoa học tốt nhất hiện nay. Ở bài thi hỏi đáp kiến thức nâng cao GPQA Diamond (ngăn chặn tra cứu Google), GPT‑5.2 Pro đạt 93.2%, GPT‑5.2 Thinking đạt 92.4%.
Trên FrontierMath (Tier 1–3), bài kiểm tra toán học chuyên sâu, GPT‑5.2 Thinking cũng lập kỷ lục mới với 40.3% bài giải thành công.
Trên ARC-AGI-1 (Verified), bài kiểm tra lý luận tổng quát, GPT‑5.2 Pro là mô hình đầu tiên vượt ngưỡng 90%, cải thiện đáng kể so với 87% của o3‑preview năm ngoái, đồng thời giảm chi phí để đạt hiệu quả này tới 390 lần.
Trên ARC-AGI-2 (Verified) – bài kiểm tra khó hơn và tập trung vào năng lực lý luận linh hoạt – GPT‑5.2 Thinking đạt chuẩn mới với 52.9%. GPT‑5.2 Pro còn nhỉnh hơn ở mức 54.2%, mở rộng khả năng giải quyết các vấn đề trừu tượng mới.
Những tiến bộ trên các bảng đánh giá này thể hiện năng lực lý luận đa bước mạnh mẽ, độ chính xác cao và khả năng giải quyết bài toán kỹ thuật phức tạp một cách đáng tin cậy của GPT‑5.2.
GPT‑5.2 trên ChatGPT
Trên ChatGPT, người dùng sẽ cảm nhận được GPT‑5.2 thân thiện và hiệu quả hơn mỗi ngày – với cấu trúc trả lời rõ ràng, đáng tin cậy, vẫn giữ được phong cách đối thoại tự nhiên.
GPT‑5.2 Instant là lựa chọn “siêu tốc” cho công việc và học tập hàng ngày, cải thiện rõ rệt ở các câu hỏi tìm kiếm thông tin, hướng dẫn, viết kỹ thuật, dịch thuật – kế thừa phong cách hội thoại thân thiện từ GPT‑5.1 Instant. Người dùng đánh giá cao các lời giải thích dễ hiểu, đưa thông tin trọng tâm ngay từ đầu.
GPT‑5.2 Thinking được tối ưu cho các nhiệm vụ phức tạp, giúp giải quyết công việc chất lượng cao hơn – đặc biệt ở các tác vụ lập trình, tóm tắt tài liệu dài, trả lời câu hỏi về file tải lên, giải toán hoặc logic nhiều bước, lên kế hoạch và ra quyết định với cấu trúc rành mạch, chi tiết.
GPT‑5.2 Pro là lựa chọn thông minh và đáng tin cậy nhất cho những câu hỏi hóc búa, nơi chất lượng câu trả lời là yếu tố then chốt; các thử nghiệm cho thấy số lỗi lớn giảm hẳn và hiệu suất vượt trội trong các lĩnh vực khó như lập trình.
An toàn
GPT‑5.2 tiếp tục phát triển trên nền tảng nghiên cứu về an toàn từng được giới thiệu cùng GPT‑5, giúp đưa ra các câu trả lời vừa hữu ích vừa đảm bảo an toàn.
Trong bản phát hành này, chúng tôi tiếp tục tăng cường năng lực xử lý những tình huống nhạy cảm, đặc biệt cải thiện cách mô hình phản hồi với các tín hiệu liên quan đến ý định tự tử, tự làm hại, khủng hoảng tâm lý hoặc phụ thuộc cảm xúc vào AI. Những cải tiến này giúp giảm đáng kể các câu trả lời không mong muốn ở cả GPT‑5.2 Instant lẫn GPT‑5.2 Thinking so với GPT‑5.1. Thông tin chi tiết có trong system card.
Chúng tôi cũng đang triển khai giai đoạn đầu của mô hình dự đoán độ tuổi, tự động bảo vệ người dùng dưới 18 tuổi khỏi nội dung nhạy cảm, bổ sung vào các biện pháp xác minh độ tuổi và kiểm soát của phụ huynh hiện có.
GPT‑5.2 là bước tiến tiếp theo trong chuỗi cải tiến không ngừng và chúng tôi sẽ còn tiếp tục. Dù phiên bản này đã cải thiện đáng kể về trí thông minh và hiệu suất, chúng tôi hiểu kỳ vọng của người dùng còn cao hơn nữa. Trên ChatGPT, chúng tôi đang giải quyết các vấn đề như từ chối quá mức, đồng thời tiếp tục nâng chuẩn an toàn và độ tin cậy. Đây là các thay đổi phức tạp, nên từng bước sẽ được hoàn thiện.
| GPT‑5.2 Instant | GPT‑5.1 Instant | GPT‑5.2 Thinking | GPT‑5.1 Thinking | |
|---|---|---|---|---|
| Sức khỏe tâm thần | 0.995 | 0.883 | 0.915 | 0.684 |
| Phụ thuộc cảm xúc | 0.938 | 0.945 | 0.955 | 0.785 |
| Tự hại | 0.938 | 0.925 | 0.963 | 0.937 |
Khả dụng & giá cả
Trên ChatGPT, chúng tôi bắt đầu triển khai GPT‑5.2 (Instant, Thinking, Pro) từ hôm nay, ưu tiên cho các gói trả phí (Plus, Pro, Go, Business, Enterprise). Việc triển khai sẽ dần dần để đảm bảo hoạt động ổn định; nếu chưa thấy, hãy thử lại sau. GPT‑5.1 vẫn phục vụ người dùng trả phí trong ba tháng tới dưới dạng mô hình cũ, sau đó sẽ ngừng hỗ trợ.
Trên nền tảng API, GPT‑5.2 Thinking đã sẵn sàng từ hôm nay qua Responses API và Chat Completions API với tên gpt-5.2; GPT‑5.2 Instant là gpt-5.2-chat-latest. GPT‑5.2 Pro có trên Responses API với tên gpt-5.2-pro. Nhà phát triển có thể tuỳ chỉnh mức độ reasoning cho GPT‑5.2 Pro và cả hai phiên bản Pro/Thinking đều hỗ trợ mức reasoning effort cao nhất “xhigh”, phù hợp các tác vụ đòi hỏi chất lượng tối đa.
GPT‑5.2 có giá $1.75 cho mỗi triệu tokens đầu vào và $14 cho mỗi triệu tokens đầu ra, giảm 90% cho tokens đầu vào đã cache. Trên nhiều bài kiểm tra dạng “tác vụ đa công cụ”, dù chi phí mỗi token của GPT‑5.2 cao hơn, tổng chi phí đạt chất lượng mong muốn lại thấp hơn nhờ hiệu suất vượt trội.
Giá thuê bao ChatGPT giữ nguyên, nhưng trên API, GPT‑5.2 có giá cao hơn GPT‑5.1 do năng lực mạnh hơn. Tuy nhiên, mức giá này vẫn thấp hơn nhiều mô hình tiên tiến khác, tạo điều kiện cho người dùng khai thác triệt để cho công việc và ứng dụng chủ lực.
| Model | Đầu vào | Đầu vào cache | Đầu ra |
|---|---|---|---|
| gpt-5.2 / gpt-5.2-chat-latest | $1.75 | $0.175 | $14 |
| gpt-5.2-pro | $21-$168 | ||
| gpt-5.1 / gpt-5.1-chat-latest | $1.25 | $0.125 | $10 |
| gpt-5-pro | $15-$120 | ||
Hiện tại, chúng tôi chưa có kế hoạch cụ thể về việc dừng hỗ trợ GPT‑5.1, GPT‑5 hay GPT‑4.1 trên API và sẽ thông báo trước nếu có thay đổi. GPT‑5.2 hoạt động tốt với Codex và dự kiến sẽ có phiên bản tối ưu hóa đặc biệt cho Codex trong vài tuần tới.
Đối tác
GPT‑5.2 được phát triển nhờ sự hợp tác chặt chẽ với các đối tác lâu năm là NVIDIA và Microsoft. Hạ tầng trung tâm dữ liệu Azure, GPU NVIDIA gồm H100, H200, GB200-NVL72 là nền tảng cho việc huấn luyện quy mô lớn của OpenAI, tạo động lực đột phá về trí tuệ mô hình. Nhờ hợp tác này, chúng tôi có thể mở rộng năng lực tính toán dễ dàng và đưa sản phẩm ra thị trường nhanh hơn.
Phụ lục
Dưới đây là bảng tổng hợp kết quả benchmark của GPT‑5.2 Thinking và một số chỉ số của GPT‑5.2 Pro.
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| GDPval (cho phép hòa, thắng hoặc hòa) | 70.9% | 74.1% | 38.8% (GPT-5) |
| GDPval (cho phép hòa, thắng rõ ràng) | 49.8% | 60.0% | 35.5% (GPT-5) |
| GDPval (không hòa) | 61.0% | 67.6% | 37.1% (GPT-5) |
| Bài toán bảng tính ngân hàng đầu tư (nội bộ) | 68.4% | 71.7% | 59.1% |
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| SWE-Bench Pro, Công khai | 55.6% | – | 50.8% |
| SWE-bench Verified | 80.0% | – | 76.3% |
| SWE-Lancer, IC Diamond* | 74.6% | – | 69.7% |
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| Trả lời ChatGPT không lỗi (có tìm kiếm) | 93.9% | – | 91.2% |
| Trả lời ChatGPT không lỗi (không tìm kiếm) | 88.0% | – | 87.3% |
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| OpenAI MRCRv2, 8 needle, 4k–8k | 98.2% | – | 65.3% |
| OpenAI MRCRv2, 8 needle, 8k–16k | 89.3% | – | 47.8% |
| OpenAI MRCRv2, 8 needle, 16k–32k | 95.3% | – | 44.0% |
| OpenAI MRCRv2, 8 needle, 32k–64k | 92.0% | – | 37.8% |
| OpenAI MRCRv2, 8 needle, 64k–128k | 85.6% | – | 36.0% |
| OpenAI MRCRv2, 8 needle, 128k–256k | 77.0% | – | 29.6% |
| BrowseComp Ngữ cảnh dài 128k | 92.0% | – | 90.0% |
| BrowseComp Ngữ cảnh dài 256k | 89.8% | – | 89.5% |
| GraphWalks bfs <128k | 94.0% | – | 76.8% |
| Graphwalks parents <128k | 89.0% | – | 71.5% |
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| Lý luận CharXiv (không công cụ) | 82.1% | – | 67.0% |
| Lý luận CharXiv (với Python) | 88.7% | – | 80.3% |
| MMMU Pro (không công cụ) | 79.5% | – | – |
| MMMU Pro (với Python) | 80.4% | – | 79.0% |
| Video MMMU (không công cụ) | 85.9% | – | 82.9% |
| Screenspot Pro (với Python) | 86.3% | – | 64.2% |
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| Tau2-bench Telecom | 98.7% | – | 95.6% |
| Tau2-bench Retail | 82.0% | – | 77.9% |
| BrowseComp | 65.8% | 77.9% | 50.8% |
| Scale MCP-Atlas | 60.6% | – | 44.5% |
| Toolathlon | 46.3% | – | 36.1% |
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| GPQA Diamond (không công cụ) | 92.4% | 93.2% | 88.1% |
| HLE (không công cụ) | 34.5% | 36.6% | 25.7% |
| HLE (tìm kiếm, Python) | 45.5% | 50.0% | 42.7% |
| MMMLU | 89.6% | – | 89.5% |
| HMMT, Feb 2025 (không công cụ) | 99.4% | 100.0% | 96.3% |
| AIME 2025 (không công cụ) | 100.0% | 100.0% | 94.0% |
| FrontierMath Tier 1–3 (với Python) | 40.3% | – | 31.0% |
| FrontierMath Tier 4 (với Python) | 14.6% | – | 12.5% |
| GPT-5.2 Thinking | GPT-5.2 Pro | GPT-5.1 Thinking | |
|---|---|---|---|
| ARC-AGI-1 (Verified) | 86.2% | 90.5% | 72.8% |
| ARC-AGI-2 (Verified) | 52.9% | 54.2% (cao) | 17.6% |
Các mô hình được chạy ở mức reasoning effort tối đa trên API (xhigh cho GPT‑5.2 Thinking & Pro, high cho GPT‑5.1 Thinking), riêng các bài kiểm tra chuyên môn, GPT‑5.2 Thinking chạy với reasoning effort heavy – mức tối đa trên ChatGPT Pro. Các đánh giá thực hiện trong môi trường nghiên cứu, nên kết quả có thể khác đôi chút với ChatGPT bản thương mại.
* Với SWE-Lancer, 40/237 bài không chạy được trên hạ tầng đã được loại bỏ.
Tags: GPT-5.2, AI model, Artificial Intelligence
Tags: GPT-5.2, AI model, Artificial Intelligence