Bài viết này giới thiệu 5 phương pháp thực tiễn giúp rút gọn prompt, giảm số lượng token, tăng tốc sinh văn bản từ các mô hình ngôn ngữ lớn (LLM) mà vẫn đảm bảo chất lượng đầu ra.
Các nội dung chính gồm:
- Tóm tắt ngữ nghĩa: khái niệm, thời điểm áp dụng hiệu quả
- Định dạng prompt có cấu trúc, lọc thông tin liên quan, tham chiếu hướng dẫn để giảm số lượng token
- Trừu tượng hóa mẫu và áp dụng nhất quán
Cùng tìm hiểu chi tiết từng kỹ thuật.
Giới thiệu
Các mô hình ngôn ngữ lớn (LLM) được thiết kế để tạo ra văn bản phản hồi dựa trên prompt của người dùng. Quá trình này không chỉ đơn thuần dự đoán từng token tiếp theo, mà còn cần hiểu ngữ cảnh và cấu trúc ngôn ngữ của đầu vào.
Gần đây, việc nghiên cứu các kỹ thuật nén prompt thu hút sự quan tâm lớn, nhằm giải quyết vấn đề prompt quá dài hoặc cửa sổ ngữ cảnh mở rộng khiến thời gian xử lý tăng và chi phí tốn kém. Mục tiêu là giảm số lượng token sử dụng, tăng tốc quá trình tạo văn bản mà vẫn giữ chất lượng kết quả.
Bài viết này trình bày 5 phương pháp nén prompt phổ biến, giúp đẩy nhanh tốc độ sinh văn bản của LLM trong các trường hợp phức tạp.
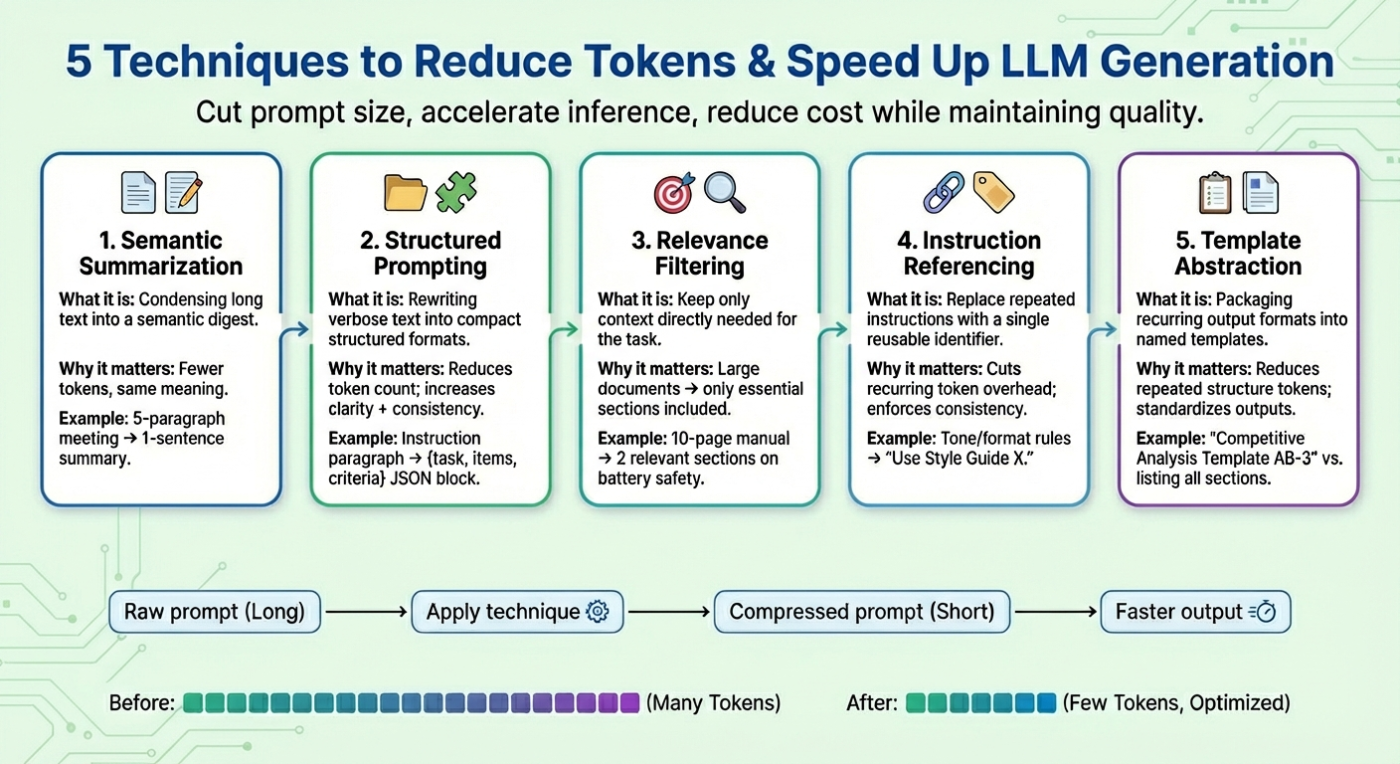
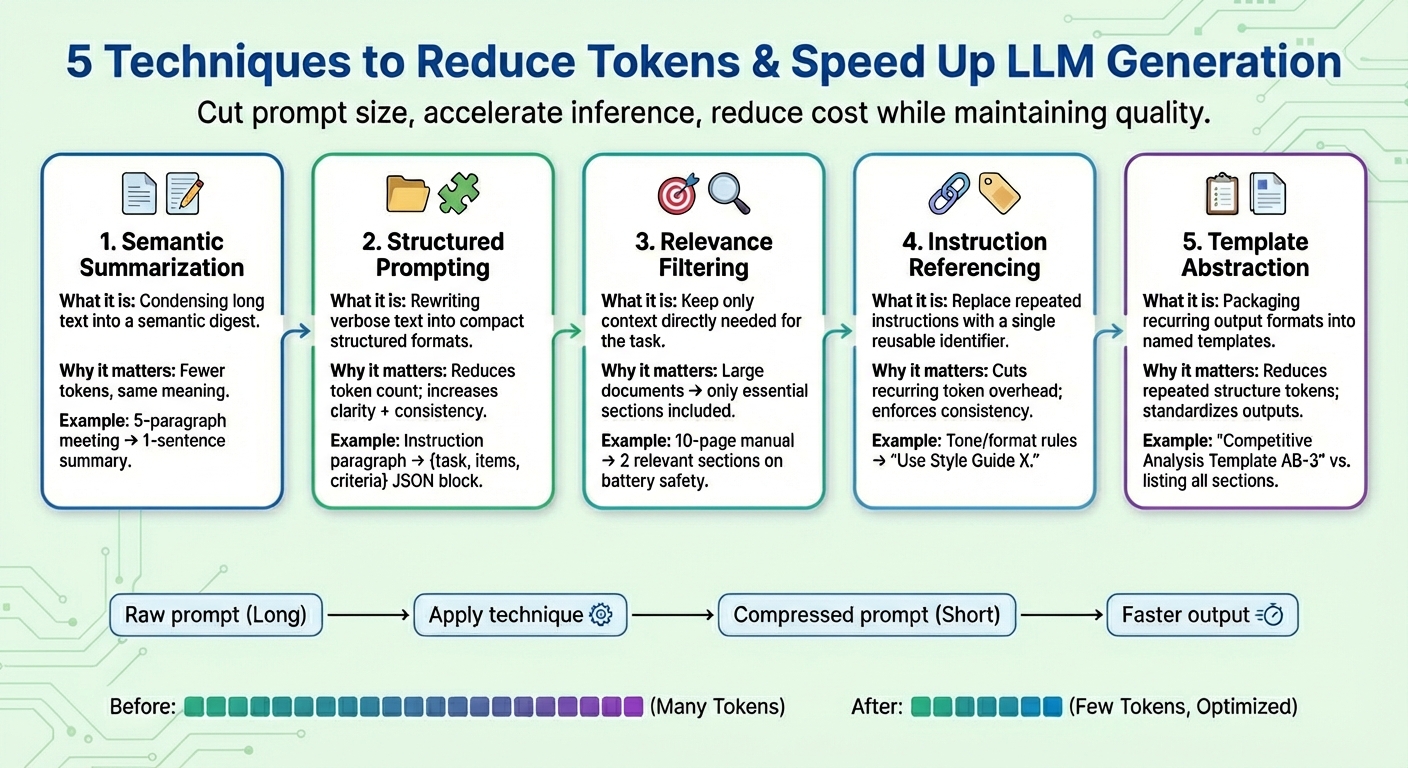
- Tóm tắt ngữ nghĩa
Tóm tắt ngữ nghĩa là cách rút gọn nội dung dài hoặc lặp lại thành một bản tóm tắt ngắn gọn, vẫn giữ được ý nghĩa chính. Thay vì đưa toàn bộ hội thoại hay tài liệu vào mô hình, chỉ cần cung cấp phần tóm tắt chứa những điểm quan trọng. Việc này giúp giảm số lượng token đầu vào, tăng tốc độ sinh văn bản và tiết kiệm chi phí mà không mất thông tin cần thiết.
Ví dụ, một prompt dạng:
“Trong cuộc họp hôm qua, Iván đã trình bày số liệu quý…”
nhiều đoạn hội thoại.
Sau khi tóm tắt ngữ nghĩa, có thể chuyển thành:
“Tóm tắt: Iván trình bày số liệu quý, nhấn mạnh doanh số Q4 giảm, đề xuất các biện pháp tiết kiệm chi phí.”
- Prompt có cấu trúc (dạng JSON)
Thay vì diễn đạt thông tin dài dòng, hãy chuyển prompt sang dạng bán cấu trúc như JSON hoặc danh sách gạch đầu dòng. Định dạng này giúp giảm số lượng token, tăng tính rõ ràng và nhất quán cho mô hình.
Ví dụ, prompt thô:
“Please provide a detailed comparison between Product X and Product Y, focusing on price, product features, and customer ratings.”
Sau khi chuyển sang dạng cấu trúc:
{
"task": "compare",
"items": ["Product X", "Product Y"],
"criteria": ["price", "features", "ratings"]
}
- Lọc thông tin liên quan
Chỉ đưa vào prompt những phần thực sự liên quan đến nhiệm vụ, thay vì toàn bộ tài liệu. Việc này giúp giảm dung lượng prompt và tăng độ chính xác khi sinh văn bản.
Ví dụ: Một hướng dẫn sử dụng điện thoại dài 10 trang. Sau khi lọc, chỉ giữ lại đoạn liên quan đến “thời lượng pin” và “quy trình sạc” nếu người dùng hỏi về an toàn khi sạc.
- Tham chiếu hướng dẫn
Các hướng dẫn kỹ thuật lặp lại như “viết với ngữ điệu thân thiện”, “tránh biệt ngữ”, “giữ câu súc tích”,… có thể gom lại thành một bộ hướng dẫn chung, đặt tên cố định (ví dụ: “Style Guide X”). Khi cần, chỉ cần nhắc đến tên này trong prompt, giúp rút ngắn và giữ sự nhất quán.
Ví dụ:
“Viết với ngữ điệu thân thiện. Tránh biệt ngữ. Giữ câu súc tích. Đưa ví dụ minh họa.”
Có thể thay bằng:
“Áp dụng Style Guide X.”
- Trừu tượng hóa mẫu (Template Abstraction)
Nếu thường xuyên sử dụng các mẫu báo cáo, đánh giá, quy trình…, hãy gom các mẫu này thành một tên gọi chung, mô tả sẵn các phần cần có. Khi tạo prompt, chỉ cần tham chiếu tên mẫu, LLM sẽ tự điền nội dung chi tiết.
Ví dụ:
“Hãy tạo phân tích đối thủ cạnh tranh theo Mẫu AB-3.”
Trong đó, mẫu AB-3 quy định:
- Tổng quan thị trường (2–3 đoạn tóm tắt)
- Phân tích đối thủ (bảng so sánh ít nhất 5 đối thủ)
- Điểm mạnh và điểm yếu (liệt kê)
- Khuyến nghị chiến lược (3 bước hành động cụ thể)
Tổng kết
Trên đây là 5 cách phổ biến giúp rút gọn prompt, giảm số lượng token, tối ưu tốc độ và chi phí khi dùng LLM, đặc biệt hiệu quả với các tác vụ phức tạp, nhiều ngữ cảnh.
Tham khảo thêm các gợi ý ChatGPT sáng tạo nội dung hay nhất của tôi


](https://ainextvibe.com/wp-content/uploads/2026/01/e138d9cfc3a24beb958b4734b899715b.jpg)
