Nghiên cứu mới tại NeurIPS 2025 chỉ ra rằng các phương pháp tự học (tự giám sát) giúp Vision Transformer (ViT) nắm bắt hình ảnh tốt hơn so với cách huấn luyện có giám sát truyền thống.

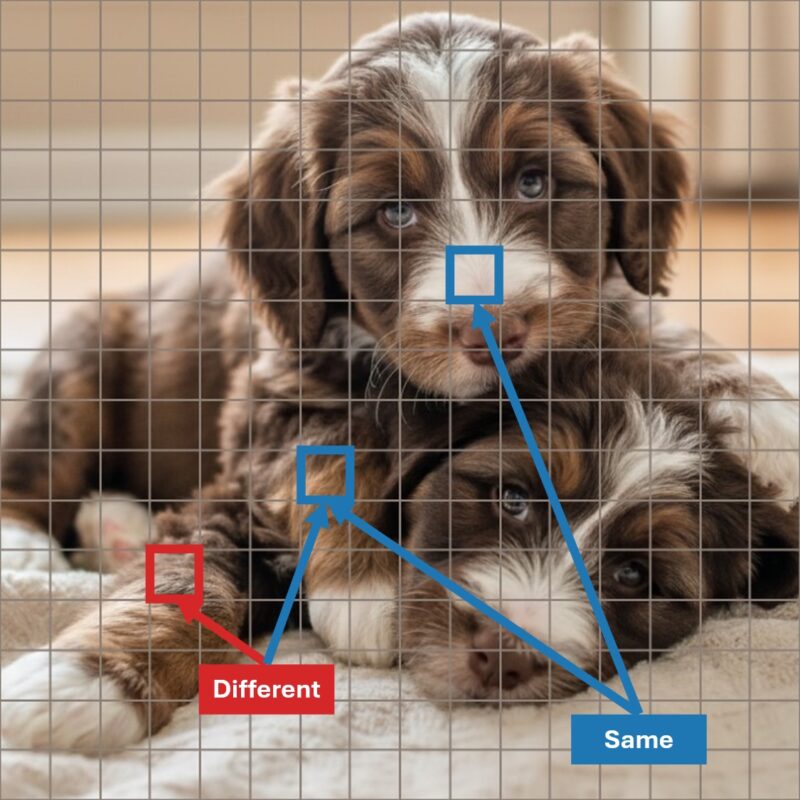
Minh họa: Phân biệt các mảnh hình ảnh thuộc cùng một chú chó con hoặc khác nhau.
Bài báo từ nhóm của Konrad Körding [1], “Does Object Binding Naturally Emerge in Large Pretrained Vision Transformers?” đặt ra vấn đề sâu sắc trong khoa học thần kinh thị giác: Làm sao não (hay AI) liên kết các yếu tố và kết cấu thành một đối tượng thống nhất? Dưới đây là tổng quan lý thuyết, tóm tắt nghiên cứu mới tại NeurIPS, cùng những phân tích giúp bạn hiểu rõ hơn về mạng nơ-ron nhân tạo và so sánh với hệ thần kinh sinh học. Bài viết cũng giải thích các phương pháp tự giám sát trong học sâu, mô hình Visual Transformer, và những khác biệt giữa cách học của AI hiện nay với bộ não người.
1. Giới thiệu
Khi quan sát một cảnh vật, hệ thống thị giác của con người không chỉ nhận diện các đối tượng và bố cục tổng thể, mà còn tiếp cận được toàn bộ các tầng xử lý từ thấp đến cao.
Chúng ta có thể tập trung vào một đối tượng cụ thể nhờ các vùng cao cấp như vỏ não thái dương dưới (IT) và vùng nhận diện khuôn mặt (FFA), đồng thời vẫn truy xuất được những thông tin chi tiết như đường viền, kết cấu tại các vùng thấp hơn (V1, V2).
Nếu không thể truy cập toàn bộ các tầng này, chúng ta sẽ hoặc mất đi khả năng nhận biết chi tiết, hoặc khiến các tầng cao cấp phải xử lý quá nhiều thông tin, dẫn đến “bùng nổ số chiều” – một vấn đề khiến bộ não phải lớn hơn và tiêu tốn nhiều năng lượng.
Việc các thông tin thị giác được phân tán trong hệ thần kinh đòi hỏi các thành phần trong cảnh phải được liên kết lại. Có hai giả thuyết chính về cách liên kết này: Một trường phái cho rằng liên kết dựa vào sự đồng bộ (dao động thần kinh), trường phái còn lại cho rằng chỉ cần tăng tần suất phát xung của các neuron là đủ. Tôi theo trường phái thứ hai, vốn do Rüdiger von der Heydt, Ernst Niebur và Pieter Roelfsema phát triển.
Von der Malsburg và Schneider từng đề xuất từ 1986 rằng mỗi đối tượng có nhãn thời gian riêng [2]. Khi nhìn hai chú chó con, các neuron mã hóa chú chó thứ nhất sẽ phát xung ở một pha dao động, còn các neuron mã hóa chú chó thứ hai ở pha khác. Bằng chứng kiểu liên kết này chủ yếu được thấy ở mèo bị gây mê – mà gây mê lại làm tăng dao động não.
Ở trường phái tần suất phát xung, các neuron mã hóa đối tượng được chú ý sẽ phát xung mạnh hơn các neuron mã hóa đối tượng không được chú ý, và các neuron mã hóa đối tượng dù chú ý hay không cũng hoạt động mạnh hơn neuron nền. Điều này đã được xác nhận nhiều lần trên động vật tỉnh táo [3].
Lúc đầu, nhiều thí nghiệm ủng hộ giả thuyết đồng bộ/dao động, nhưng càng về sau, dữ liệu lại nghiêng về giả thuyết tần suất phát xung.
Nghiên cứu của Li tập trung vào việc liệu các mô hình học sâu có hình thành khả năng liên kết đối tượng hay không. Họ chứng minh rằng ViT huấn luyện bằng tự giám sát tự nhiên học được cách liên kết các thành phần của đối tượng, trong khi ViT huấn luyện bằng phân loại có giám sát (ImageNet) thì không. Theo tôi, việc chỉ dùng một hàm mất mát toàn cục khi lan truyền ngược là điểm yếu lớn. Nếu không thiết kế kỹ lưỡng, mô hình sẽ học những đặc điểm dễ nhận diện (như kết cấu) thay vì bản chất của đối tượng, như Geirhos et al. từng chỉ ra [4]. Điều này khiến mô hình dễ bị tấn công và chỉ chú ý đến các yếu tố tác động mạnh đến kết quả. May mắn thay, học tự giám sát khắc phục được vấn đề này và thực sự giúp mô hình học liên kết đối tượng.
2. Phương pháp
2.1. Giới thiệu kiến trúc Vision Transformer (ViT)
ViT (Vision Transformer; [5]) là mô hình chia nhỏ ảnh thành nhiều mảnh nhỏ (patch), rồi chuyển mỗi mảnh thành một vector đặc trưng (token). Trong nghiên cứu của Li, ảnh được chuẩn hóa về \(224\times224\) pixel và chia thành lưới \(16\times16\) mảnh (\(14\times14\) pixel/mảnh). Mỗi mảnh được chuyển thành token bằng cách “duỗi” thành vector.
Vị trí từng mảnh được mã hóa qua embedding vị trí để đảm bảo mô hình nhận diện được vị trí không gian của từng phần. Khi thực hiện phân loại, chuỗi token sẽ thêm một token đặc biệt dành cho phân loại. Với \(W \times H\) mảnh, đầu vào gồm \(1 + W \times H\) token. Token đầu tiên (phân loại) được sử dụng để dự đoán nhãn, các token còn lại bị bỏ qua. Trong quá trình huấn luyện, mô hình học cách nén thông tin toàn ảnh vào token phân loại này.
Các token sau đó được truyền qua các tầng encoder của Transformer, giữ nguyên độ dài chuỗi. Tuy không bắt buộc token ở từng vị trí sẽ mã hóa nội dung gì, nhưng phương pháp huấn luyện sẽ ảnh hưởng đến việc này. Với các nhiệm vụ “dày đặc” như MAE, mô hình bị ép phải giữ sự tương ứng giữa token đầu vào và đầu ra, còn với nhiệm vụ “thô” như phân loại thì không.
2.2. Chế độ huấn luyện: Học tự giám sát (SSL)
Nghiên cứu này sử dụng nhiều phương pháp tự giám sát, gồm DINO, MAE, CLIP – tất cả đều cho kết quả nhất quán.
DINOv2 là phương pháp chính được kiểm tra. DINO sử dụng kỹ thuật biến đổi dữ liệu (crop, thay đổi màu sắc…) để mô hình phải tìm ra các thông tin quan trọng, đảm bảo các phiên bản biến đổi có thể được ánh xạ về cùng một biểu diễn. DINO duy trì hai mạng: một mạng “thầy” (EMA của mạng “trò”), giúp tránh việc mô hình tự đồng nhất biểu diễn một cách sai lệch.
MAE là dạng Masked Image Modelling: một phần token/mảnh bị loại bỏ khỏi đầu vào; các token còn lại được dùng để dự đoán lại các phần bị che đi. Hàm mất mát so sánh token dự đoán với token gốc.
CLIP dựa vào dữ liệu ảnh có caption. Encoder ảnh và encoder văn bản được huấn luyện đồng thời để đưa biểu diễn ảnh và caption về gần nhau trong không gian đặc trưng. Tuy là tự giám sát, CLIP vẫn sử dụng tín hiệu giám sát yếu (caption).
2.3. Cách kiểm tra mô hình (Probe)

Hình minh họa: Hai chú chó với các mảnh cùng đối tượng (xanh), khác đối tượng (đỏ-xanh).
Để kiểm tra liên kết đối tượng, nhóm nghiên cứu dùng các phép đo tương đồng giữa các mảnh hình ảnh (ví dụ, cosine similarity). Nhưng điều này chưa đủ để khẳng định mô hình thực sự nhận diện liên kết đối tượng, vì có thể chỉ phản ánh đặc điểm cấp thấp hoặc lớp đối tượng. Do đó, cần có các phép kiểm tra (probe) có thể phân biệt các mảnh cùng lớp ngữ nghĩa nhưng khác thực thể.
Các probe chính được sử dụng gồm diagonal quadratic probe và quadratic probe. Quadratic probe bổ sung thêm lớp chiếu tuyến tính và thực hiện phép nhân vô hướng, cho phép “chiếu” các vector đặc trưng vào không gian mới để kiểm tra liên kết. Ngoài ra, các probe dựa trên lớp đối tượng được sử dụng làm baseline mạnh.

Hình minh họa: Độ chính xác của việc phát hiện liên kết đối tượng qua các lớp mạng (kết quả với DINOv2).
Kết quả cho thấy quadratic probe vượt trội so với các baseline đối tượng kể từ lớp thứ 10-11 (trong tổng số 23 lớp). Diagonal quadratic probe không vượt nổi baseline, cho thấy cần ít nhất một lớp chiếu tuyến tính để phát hiện liên kết đối tượng.
3. Kết quả chính: Li et al. (2025)
Khẳng định cốt lõi của bài báo là: ViT huấn luyện bằng tự giám sát tự nhiên hình thành khả năng liên kết đối tượng, trong khi ViT huấn luyện bằng phân loại ImageNet lại rất yếu ở khía cạnh này. Đối với mô hình ViT huấn luyện có giám sát, độ chính xác phát hiện liên kết chỉ nhỉnh hơn baseline yếu 3,7% – gần như không có khả năng liên kết.
Điểm đáng chú ý là DINOv2 và MAE buộc mô hình giữ sự tương ứng giữa token đầu vào và đầu ra, còn huấn luyện phân loại ImageNet thì không. Các probe giả định token thứ \(i\) ở một lớp nào đó sẽ khớp với token cùng vị trí đầu vào, điều này đúng hơn với mô hình huấn luyện tự giám sát.
Với CLIP và MAE, vẫn cần kiểm tra thêm với baseline mạnh hơn để khẳng định khả năng liên kết đối tượng. Ở CLIP, tín hiệu liên kết không rõ ràng, bởi phương pháp này cũng không ép mô hình bảo toàn sự tương ứng token qua các lớp.
So với bộ não người, liên kết đối tượng là bài toán khó vì biểu diễn đối tượng bị phân tán nhiều tầng xử lý. Kiến trúc ViT lại đi theo hướng một chiều: thông tin truyền từ dưới lên, không có luồng thông tin hai chiều như não bộ. Dù vậy, kết quả cho thấy quadratic probe vẫn phát hiện được liên kết ở các lớp giữa của mạng, chứng tỏ thông tin này vẫn tồn tại.
4. Kết luận: Định nghĩa lại “Hiểu” trong AI?
Đây là nghiên cứu rất đáng chú ý, lần đầu chứng minh mô hình học sâu có thể hình thành liên kết đối tượng. Nếu kiểm tra thêm với các phương pháp như MAE, baseline mạnh hơn, kết quả sẽ càng thuyết phục. Việc ViT huấn luyện tự giám sát (DINO) có khả năng liên kết đối tượng, trong khi ViT phân loại ImageNet thì không, xác nhận các quan sát trước về mô hình CNN bị lệch về kết cấu thay vì hình dạng đối tượng [4]. ViT ít bị lệch kết cấu hơn [6], và DINO tự học cũng giảm lệch kết cấu (MAE có thể không) [7].
Nghiên cứu luôn có thể mở rộng và hoàn thiện hơn. Việc tách biệt liên kết đối tượng với các đặc trưng khác cần những kiểm tra tinh vi hơn (có thể dùng hình học nhân tạo), nhưng bằng chứng hiện tại đã rất mạnh.
Ngay cả khi bạn không quan tâm đến liên kết đối tượng, sự khác biệt giữa ViT tự học và có giám sát cũng đem lại bài học quan trọng về cách huấn luyện mô hình AI. Các mô hình nền tảng đang tiến gần hơn với chuẩn trí thông minh thực – con người.
Tham khảo
- Nhận xét NeurIPS: https://openreview.net/forum?id=5BS6gBb4yP
- Mã nguồn: https://github.com/liyihao0302/vit-object-binding
- https://kording.substack.com/
- Tham khảo thêm các gợi ý ChatGPT sáng tạo nội dung hay nhất của tôi
Phụ lục: Giải thích chi tiết các probe
Để kiểm tra hai token có liên kết hay không, có thể tính cosine similarity giữa các vector đặc trưng đã chuẩn hóa. Trong nghiên cứu, nhóm sử dụng diagonal quadratic probe (dot-product với trọng số học được) và quadratic probe (chiếu tuyến tính rồi lấy dot-product):
- Diagonal quadratic probe:
$$
\phi_\text{diag} (x, y) = x ^ \top\mathrm{diag} (w) y
$$
Trong đó trọng số \(w\) được học, giúp tập trung vào các chiều liên quan.
- Quadratic probe:
$$
\begin{align}
\phi_\text{quad} (x, y) &= W x \cdot W y \\
&= \left( W x \right) ^ \top W y \\
&= x ^\top W ^\top W y
\end{align}
$$
với \(W \in \mathbb R ^{k \times d}, k \ll d\).
Quadratic probe cho kết quả tốt hơn nhiều khi trích xuất liên kết đối tượng so với diagonal quadratic probe. Linear probe (áp dụng lớp tuyến tính rồi cộng hai token) không hiệu quả bằng quadratic probe vì phép cộng không phù hợp cho kiểm tra liên kết.
Tài liệu tham khảo
[1] Y. Li, S. Salehi, L. Ungar và K. P. Kording, Does Object Binding Naturally Emerge in Large Pretrained Vision Transformers? (2025), arXiv:2510.24709
[2] P. R. Roelfsema, Giải quyết vấn đề liên kết: Nhóm neuron hình thành nhờ tăng tần suất phát xung – không cần dao động hay đồng bộ (2023), Neuron, 111(7), 1003-1019
[3] J. R. Williford và R. von der Heydt, Mã hóa quyền sở hữu biên (2013), Scholarpedia journal, 8(10), 30040
[4] R. Geirhos, P. Rubisch, C. Michaelis, M. Bethge, F. A. Wichmann và W. Brendel, CNN huấn luyện bằng ImageNet bị lệch về kết cấu; tăng lệch hình dạng cải thiện độ chính xác và độ bền (2018), Hội nghị Quốc tế về Biểu diễn Học
[5] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., Vision Transformer cho nhận diện ảnh quy mô lớn (2020), arXiv:2010.11929
[6] M. M. Naseer, K. Ranasinghe, S. H. Khan, M. Hayat, F. Shahbaz Khan và M. H. Yang, Đặc tính của Vision Transformer (2021), Advances in Neural Information Processing Systems, 34, 23296-23308
[7] N. Park, W. Kim, B. Heo, T. Kim và S. Yun, Vision Transformer tự giám sát học được gì? (2023), arXiv:2305.00729