Ảnh: Future
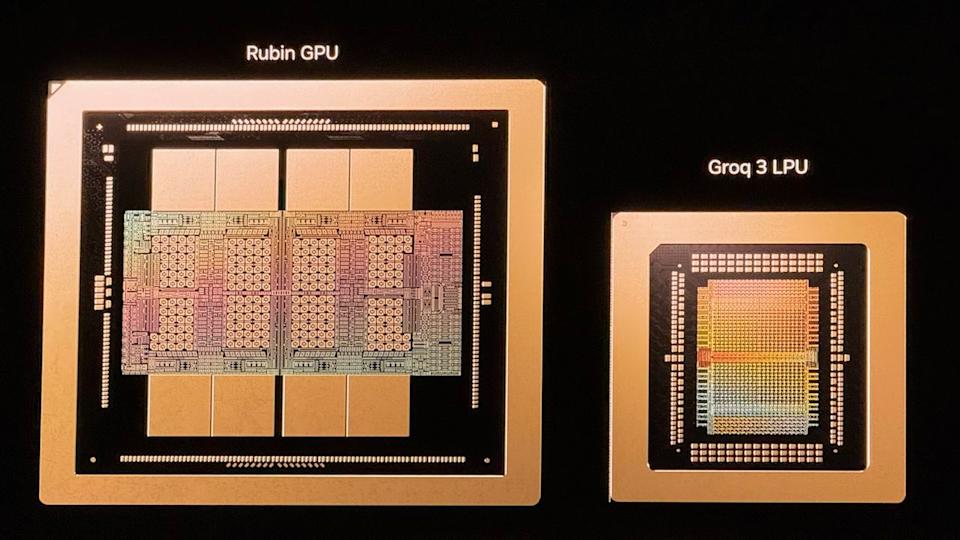
Nền tảng Vera Rubin của Nvidia đang chuẩn bị mang lại sức mạnh khổng lồ cho thế hệ tiếp theo của các trung tâm dữ liệu AI—mà CEO Jensen Huang gọi là “AI factories”—khi các hệ thống này bắt đầu giao hàng vào cuối năm nay. Trong bài phát biểu khai mạc GTC, Huang tiết lộ rằng Nvidia đang sử dụng IP mua lại từ Groq năm ngoái để mở rộng khả năng của nền tảng Rubin. Rubin giờ đây bao gồm một chip mới, Nvidia Groq 3 LPU, một bộ tăng tốc suy luận (inference accelerator) giúp tăng khối lượng token cung cấp và giảm độ trễ cho các mô hình AI có tính tương tác cao.
Nền tảng Rubin hiện đã tích hợp sáu loại chip, được lắp ghép thành các hệ thống quy mô rack:
- GPU Rubin
- CPU Vera
- Switch mở rộng NVLink 6
- Smart NIC ConnectX 9
- Đơn vị xử lý dữ liệu Bluefield 4
- Switch mở rộng Spectrum‑X có quang học đồng gói
Groq 3 LPU là một khối xây dựng nữa được thêm vào Rubin ở quy mô lớn.
Khác với hầu hết các bộ tăng tốc AI dựa vào HBM làm tầng bộ nhớ chính, mỗi Groq 3 LPU được trang bị 500 MB SRAM, cùng loại bộ nhớ đệm siêu nhanh mà CPU và GPU cũng sử dụng. Mặc dù dung lượng này khiêm tốn so với 288 GB HBM4 trên mỗi GPU Rubin, SRAM lại cung cấp băng thông 150 TB/s, vượt xa 22 TB/s của HBM. Lợi thế băng thông khổng lồ này đặc biệt hữu ích cho các tác vụ giải mã AI nhạy cảm với băng thông.
Nvidia sẽ lắp ráp các kệ Groq 3 LPX chứa 256 LPU Groq 3. Mỗi kệ cung cấp 128 GB SRAM với băng thông 40 PB/s cho việc tăng tốc suy luận và kết nối các chip qua một giao diện mở rộng riêng biệt, đạt 640 TB/s cho mỗi kệ.
Ảnh: Future
Nvidia hình dung Groq LPX sẽ là bộ xử lý phụ cho Rubin, giúp tăng hiệu năng giải mã tại mỗi lớp của mô hình AI trên mọi token, theo lời Ian Buck, Phó Chủ tịch Hyperscale của Nvidia. Điều này đặt Rubin vào vị trí phục vụ ranh giới mới của AI: hệ thống đa‑tác‑nhân cần hiệu năng tương tác trong khi suy luận các mô hình có hàng nghìn tỷ tham số và cửa sổ ngữ cảnh lên tới hàng triệu token.
Trong các kịch bản đa‑tác‑nhân, tốc độ sinh token cần thiết cho giao tiếp AI‑to‑AI cao hơn rất nhiều so với các chatbot hướng đến người dùng. Sự kết hợp giữa GPU Rubin và LPU Groq có thể tăng năng suất từ khoảng 100 token/giây lên 1 500 TPS hoặc hơn.
Việc bổ sung Groq 3 LPU củng cố vị thế của Rubin trong thị trường suy luận độ trễ thấp, nơi các đối thủ như Cerebras—sử dụng wafer‑scale engine với SRAM khổng lồ—đã thách thức các GPU của Nvidia. Một số khách hàng, trong đó có OpenAI, đã triển khai Cerebras cho các công việc đòi hỏi độ trễ cực kỳ quan trọng.
Buck gợi ý rằng Groq 3 LPU có thể làm giảm vai trò của bộ tăng tốc suy luận CPX của Rubin, vì hai chip đều nhằm mục tiêu tăng cường hiệu năng tương tự, trong khi LPU Groq không cần bộ nhớ GDDR7 lớn như các mô-đun CPX.
Chúng tôi đang có mặt tại GTC tuần này, khám phá cách sự kết hợp giữa Groq và IP của Nvidia sẽ định hình tương lai của suy luận AI.
Tags: Nvidia, AI Inference, Data Center